

О задании
В ЕГЭ по информатике 2025 года задание 27 было кардинально изменено. Если ранее оно было самым трудным во всем экзамене и подразумевало применение методов олимпиадного программирования, то в настоящее время с ним может справиться любой экзаменуемый, просто выучив один из трёх алгоритмов.
Задания 27 теперь нацелены на кластеризацию данных и вычисление параметров кластеров. В данном задании вам даются два файла, которые содержат в каждой строке абсциссу и ординату точки. Эти точки следует разделить на кластеры и вычислить для каждого кластера заданное в условие значение. Обычно в качестве ответа требуется дать среднее арифметическое абсцисс и ординат медоид кластеров (в условии задания они называются «центрами»).
Таким образом, все решение этого задания заключается в трёх шагах:
- Прочитать и обработать данные из файла (привести к нужному типу, заменить запятые на точки при необходимости)
- Провести кластеризацию данных, то есть разделить все данные на группы по схожим признакам
- В получившихся кластерах найти медоиды и вычислить среднее арифметическое по их координатам
Ко всему прочему, если ранее в 27 заданиях были файлы A и Б такие, что решение второго файла необходимо было существенно переделывать и оптимизировать, то в новых заданиях данные в файлах практически ничем не отличаются.
В большинстве случаев вам предстоит просто поменять название входного файла в коде, и та же самая программа выдаст верный ответ как к первому, так и ко второму файлу.
Вернёмся к описанным выше шагам. С первым шагом все и так понятно – с файлами мы уже умеем работать. Медоиды всегда ищутся по одному и тому же алгоритму, который описан в условии задания, здесь ничего необычного мы не сможем привнести. Но с алгоритмами кластеризации все куда интереснее.
Задание №8087

скачиваем файлы

папку можно создать заранее или при выборе директории

Далее в папке со скаченным файлом создаете пустой документ электронной таблицы. Я буду использовать Excel.

У вас должно получиться примерно также

открываем документ Excel
и обязательно меняете на «все файлы»

выбираем наш файл

с разделителями

обязательно на будущее — ставьте разделитель пробел, если столбцов несколько ( у нас два)

далее
готово

после этого выделяем первую строку (просто кликнуть левой кнопкой на цифре 1) далее правой кнопкой — вставить

появляется новая строка сверху

в A1 пишем x, в B1 — y

далее выделяем два наших столбца — наведите левую кнопку мыши на букву A, зажмите левую кнопку и проведите до B

после этого переходим на вкладку вставка — диаграммы — точечная — и самая первая

появляется диаграмма

отдельно её анализируем

сразу видно, что нижний и верхний кластеры можно разбить по условию y > 10 или y < 10
если хотите по оси x, то тут примерно x < 16 или x > 16
нам нужно это для того, чтобы вытащить координаты кластеров в отдельную таблицу
я начну с левого нижнего y < 10
в столбец C пишем формулу =B2<10

нажимаем enter
наводим курсор мыши на правый нижний угол ячейки (должен появиться крестик) и два раза кликаем левой кнопкой мыши
формулы автоматически продлятся на весь диапазон

кликаем левой кнопкой мыши на ячейке C1
после этого в правом верхнем углу окна программы на вкладке главная находим сортировка и фильтр
выбираем фильтр

на ячейках первой строки появляются кнопочки вызова контекстного меню фильтрации
так как я ищу соответствие условию =B2<10, то выбираю только ИСТИНА

после нажатия на ОК фильтрация оставит на виду только координаты левого кластера

далее хитрый ход — правильно выделить и, главное, правильно скопировать и вставить данные
по примеру выше (где выделяли два столбца) выделяем столбцы A и B

ctrl + C или правой кнопкой — копировать

в левом нижнем углу окна программы видим вкладки (пока одну и рядом справа плюсик)

нажимаем на плюсик, кликаем два раза левой кнопкой мыши на Лист1 и пишем название (например left)

если совсем гибель — не кликается и тд — правой кнопкой — переименовать

далее нажимаете правой кнопкой на пустой ячейке A1 созданного листа left
и выбираете вставить только значения (рисуночек с 123)

чтобы пропало это странное выделение

нужно просто кликнуть где-нибудь на пустую ячейку, нажать пробел, удалить его и все — выделение пропадет

теперь аналогично делаем для правого кластера





переходим к самому захватывающему этапу — написанию формулы для поиска центроида
для удобства копируем формулу win + shift + S
и вставляем справа в таблице, чтобы видеть ее перед собой

формула простая, но есть один нюанс — её нужно выучить, отработать и запомнить волшебные комбинации клавиш
это далее
сначала пишем формулу — помните!!! в Excel дробная часть отделяется запятой

0,5 — квадратный корень

после этого важно !!!
выделяем часть диапазона x

и нажимаем ctrl + shift + стрелочка вниз
мы окажемся автоматически внизу

справа за ползунок перемещаемся вверх

и УРА! диапазон прописался

выделаем диапазон

и нажимаем клавишу F4 (на клавиатуре сверху — если ноутбук — будьте внимательны к Fn)
диапазон станет фиксированным — абсолютной адресацией (если что, значки доллара можно проставить вручную — долго просто)

далее

то же самое делаем и для y


получится вот такая формула

далее — ВАЖНО!!!
для применения формулы нужно нажать ctrl + shift + enter

если результат 0 — неправильно активировали горячие клавиши
далее правый угол ячейки C2 — два раза на левую кнопку
в C1 пишем res
активируем фильтр
выбираем самое наименьшее значение

это будут координаты центра левого кластера

далее для правого кластера по аналогии
только скрины




теперь по условию задачи нужно найти среднее значение координат и умножить на 10000
копируем координаты из right

вставляем их в следующую ячейку после координат left

теперь находим среднее значение двух координат
только так!!!


и умножаем на 10000 каждый результат


ОЧЕНЬ ВАЖНО!!!!
В Excel нужно расширить немного ширину ячеек, чтобы он нас не обманул значением (автоматом может округлять)
наводите курсор между буквами A и B — появляется значок с двумя стрелочками — зажимаете левую кнопку мыши и двигаете вправо, то же самое между B и C

и только теперь записываете целую часть от полученных значений
ЦЕЛУЮ часть!!
в условии было без округлений

ответы получились
В 27 заданиях можно применять один из трёх алгоритмов для кластеризации:
- Кластеризация через уравнения прямых
- Кластеризация методом k-средних
- Кластеризация методом DBSCAN
Первый алгоритм самый простой, но не практичный. Он заключается в том, что мы «очерчиваем» каждый кластер прямыми линиями и выводим уравнения этих линий. Тогда в коде проверяем, как по отношению к этим прямым лежит точка на плоскости: ниже или выше, левее или правее. То есть так же, как мы это делали в заданиях 6, когда искали количество точек внутри сложной фигуры (треугольник, шестиугольник и т.д.).
Второй метод подразумевает кластеризацию данных алгоритмом k-средних. Это некий промежуточный вариант между первым и третьим методом: он сложнее, чем первый, но проще, чем третий. При этом для использования алгоритма k-средних нам достаточно просто указать количество кластеров, которое и так задано в условии.
Недостатком этого метода является то, что он, как и первый, не может работать с выбросами и кластерами сложной формы, например, серповидными.
Третий метод самый практичный, но вместе с тем и сложный в реализации. Он основан на алгоритме DBSCAN, то есть группирует точки на основе плотности их распределения. Для работы этого алгоритма от вас потребуется только определить минимальный радиус между соседними точками (eps, «эпсилон»). Обычно он подбирается из точечной диаграммы.
Главным преимуществом алгоритма DBSCAN является то, что его можно применять к кластерам любой формы, в том числе имеющим выбросы.
Каждому из этих трёх алгоритмов будет посвящена отдельная часть этой статьи. В данной же части мы подробно рассмотрим метод кластеризации данных через уравнения прямых.
Кластеризация через уравнения прямых
Давайте разберём этот алгоритм на примере одного из 27 заданий ЕГЭ.
Задание 2702
«Фрагмент звёздного неба спроецирован на плоскость с декартовой системой координат. Учёный решил провести кластеризацию полученных точек, являющихся изображениями звёзд, то есть разбить их множество на N непересекающихся непустых подмножеств (кластеров), таких, что точки каждого подмножества лежат внутри прямоугольника со сторонами длиной H и W, причём эти прямоугольники между собой не пересекаются. Стороны прямоугольников не обязательно параллельны координатным осям.
Гарантируется, что такое разбиение существует и единственно для заданных размеров прямоугольников.
Будем называть центром кластера точку этого кластера, сумма расстояний от которой до всех остальных точек кластера минимальна. Для каждого кластера гарантируется единственность его центра. Расстояние между двумя точками на плоскости A(x1,y1) и B(x2,y2) вычисляется по формуле:
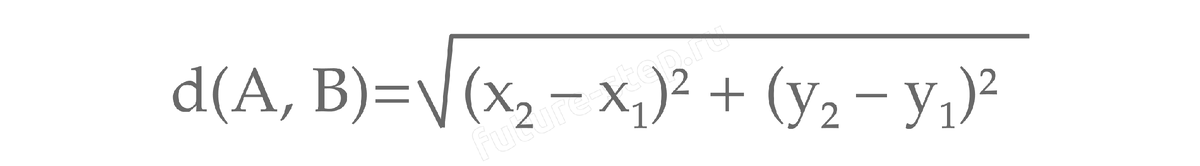
В файле A хранятся данные о звёздах двух кластеров, где H=3, W=3 для каждого кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата x, затем координата y. Значения даны в условных единицах. Известно, что количество звёзд не превышает 100.
В файле B хранятся данные о звёздах трёх кластеров, где H=3, W=3 для каждого кластера. Известно, что количество звёзд не превышает 10 000. Структура хранения информации о звездах в файле B аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа: Px – среднее арифметическое абсцисс центров кластеров, и Py – среднее арифметическое ординат центров кластеров.
В ответе запишите четыре числа: в первой строке сначала абсолютное значение целой части произведения Px ×10 000, затем абсолютное значение целой части произведения Py ×10 000 для файла А, во второй строке – аналогичные данные для файла B»
Под этой фразой скрывается термин из области кластерного анализа – медоида. Медоида — это точка (объект) из исходного набора данных, которая наиболее типична или центральна для данного набора (или кластера).
В прошлых статьях мы уже вводили термин «центроид кластера». В отличие от центроида, который может быть абстрактной точкой в пространстве (не обязательно совпадающей с реальной точкой данных), медоида всегда является одной из реальных точек.
В более математической формулировке, медоида – это элемент множества, который минимизирует сумму расстояний до всех остальных точек этого множества. Иными словами, это точка, суммарное расстояние от которой до всех других точек минимально. Именно такая интерпретация этого термина и приводится в условии задания.
Формула для нахождения расстояния между двумя точками должна быть знакома вам из школьной программы. Расстояние между двумя точками в пространстве (евклидовом) называется евклидовым расстоянием, и формула для его определения следует из теоремы Пифагора.
Можно сказать, что по этой формуле мы находим длину гипотенузы прямоугольного треугольника, катеты которого параллельны осям абсцисс и ординат, соответственно.
Рассмотрим две точки на плоскости: точку А с координатами (1, 0) и B с координатами (5, 3). Найдём расстояние между этими точками.
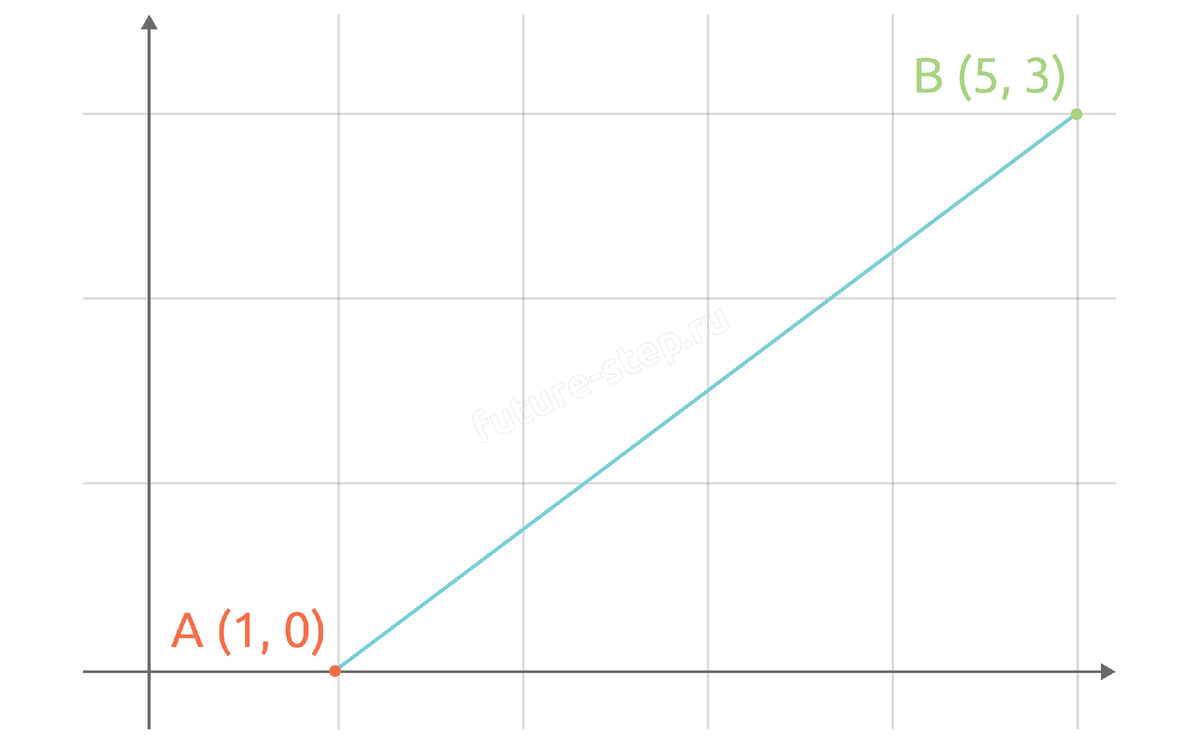
Подставляем координаты точек в формулу евклидова расстояния:

Таким образом, расстояние между нашими точками A и B равно 5 единицам.
Аналогичные действия можем проделать с помощью Python:
Аналогичные действия можем проделать с помощью Python:

Но на экзамене, в целях экономии времени рекомендуем вам пользоваться функцией dist() из встроенного модуля math. Работает она точно так же, как и наша самописная функция:

Поскольку мы теперь умеем находить расстояние между точками, давайте напишем функцию для поиска медоиды кластера. Назовём функцию get_medoid() и создадим в ней две переменные: min_distance_sum для хранения минимальной суммы расстояний и medoid_point для хранения нужной нам точки-медоиды.

Далее проходимся по каждой точке кластера и вычисляем общую сумму расстояния от этой точки до всех остальных:

Если эта сумма total_distance будет меньше предыдущей минимальной, то будем обновлять медоиду:

После завершения работы цикла будем возвращать значение medoid_point. Вся функция выглядит так:

Давайте проверим её работу на абстрактном кластере из четырёх точек:

В результате получаем медоиду нашего кластера – точку с координатами (3, 4). Но не спешите запоминать эту функцию. Её можно написать гораздо более компактно и эффективно – всего в одну строчку.

Дело в том, что функция min() в Python умеет не только находить минимальное значение в списке, но и искать минимальный элемент по какому-то правилу. Здесь это правило задаётся с помощью лямбда-функции: мы также считаем расстояния между точками p и q в кластере, последовательно перебирая каждую.
Точка p перебирается внутри самой функции min(), точка q перебирается в цикле for внутри генераторного выражения sum(dist(p, q) for q in cluster). Это генераторное выражение возвращает сумму расстояний между точками p и q, что аналогично такой записи:

В итоге мы вместо 10 строчек написали всего одну, полностью сохранив весь функционал. Давайте проверим эту функцию на все тех же данных.

Получаем все ту же точку с координатами (3, 4).
Теперь можем смело переходить к кластеризации данных. Для начала нам необходимо визуализировать все точки на диаграмме. Для этого проще всего будет воспользоваться редактором электронных таблиц.
Открываем пустую таблицу и копируем данные из прикреплённых файлов в неё. Начинаем с файла A. Получим такую диаграмму:
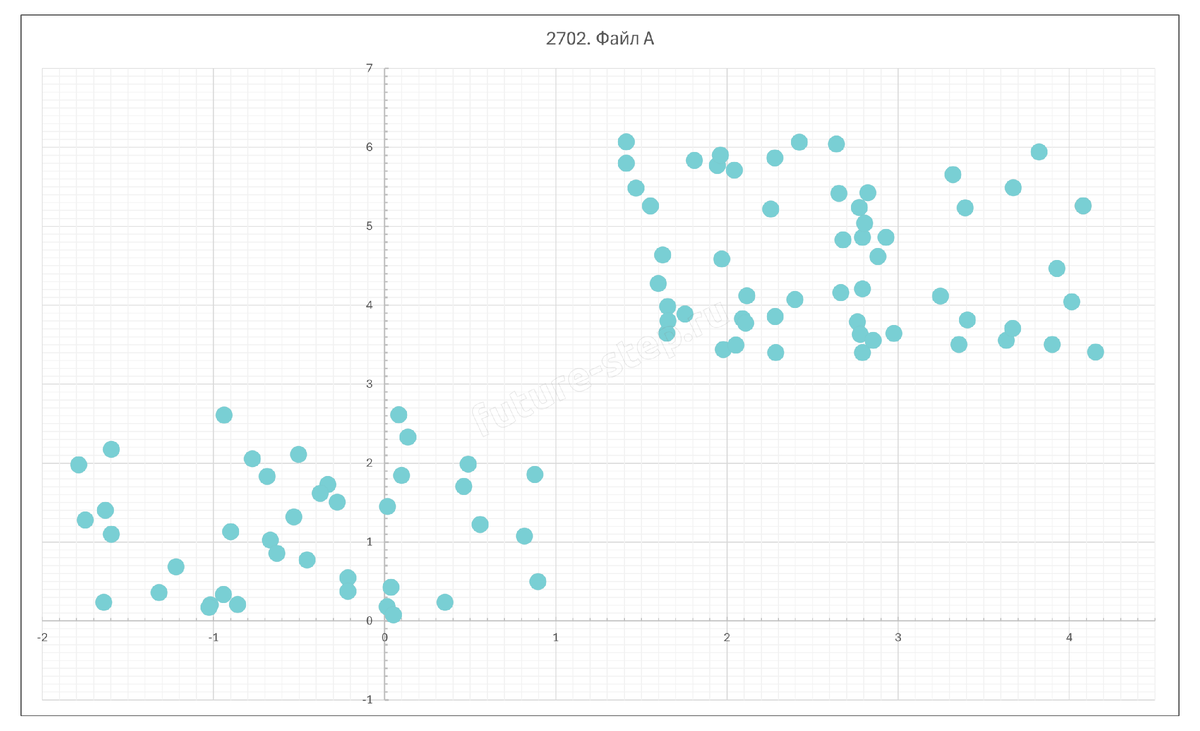
еперь нам надо очертить границы для каждой группы точек. Для левой группы будут такие границы:
- Слева: x = -1.9
- Справа: x = 1
- Снизу: y = 0
- Сверху: y = 8
Для правой, соответственно, такие границы:
- Слева: x = 1,3
- Справа: x = 4,2
- Снизу: y = 3,2
- Сверху: y = 6,2
Отметим их на изображении.
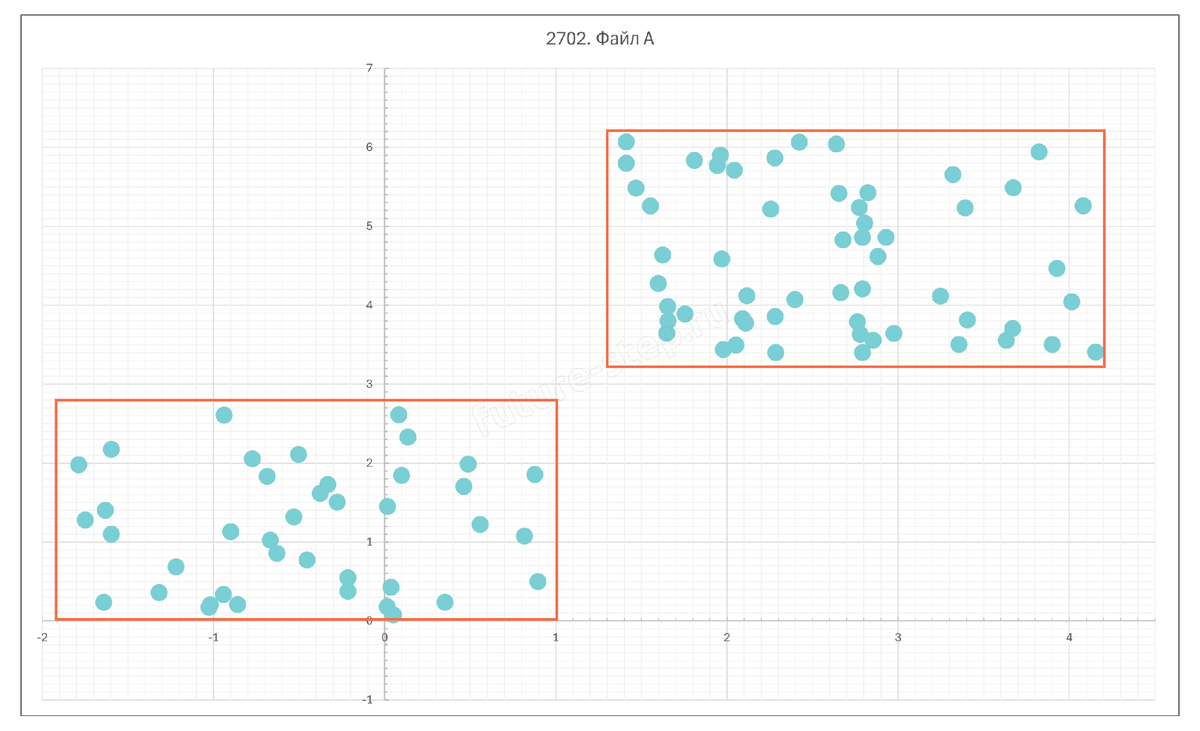
Конечно, нам такая точность в определении границ не нужна. Более того, чаще всего мы будем поступать куда проще. Например, здесь можно заметить, что кластеры разделяются всего одной прямой x = 1. Точки одного кластера лежат слева от неё, другого – справа.
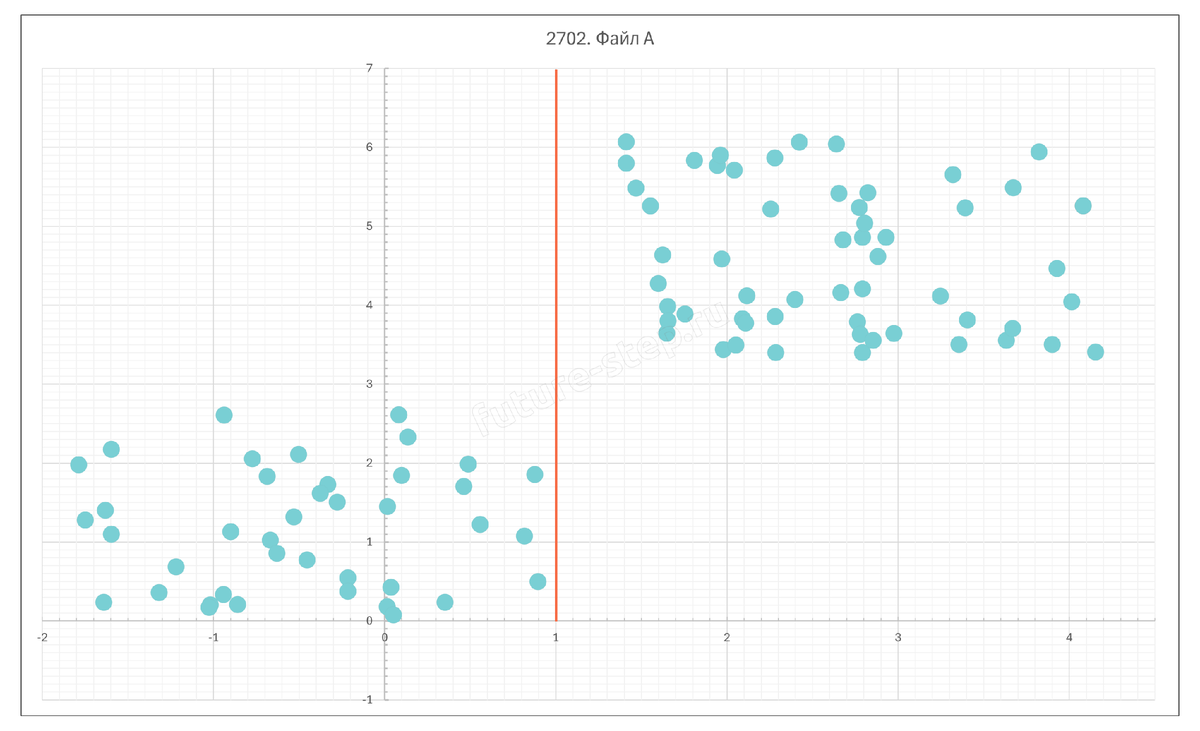
Это значит, что точки первого кластера будут иметь абсциссу меньше 1, а точки второго – больше 1.
На этом завершим наш короткий анализ данных и приступим к решению задания. Сначала импортируем функцию dist() и напишем функцию для поиска медоиды.

Теперь открываем файл А и пропускаем первую строку функцией next(). Это делаем только в тех файлах, в которых первая строка содержит буквы «X Y», а не численные данные.

Далее создаём списки под каждый кластер и в цикле for построчно считываем файл.

Разделяем числа каждой строки по пробельному символу и приводим к типу float (вещественные числа).

Если значение переменной x меньше 1, то сохраняем обе координаты в виде кортежа в первый кластер. В противном случае – во второй.

Весь код для считывания данных и их кластеризации выглядит так:

Данные мы успешно считали и разделили все точки по кластерам. Теперь переходим к поиску медоиды каждого кластера. Для этого вызываем написанную ранее функцию get_medoid().

Осталось лишь сформировать ответ. Для этого нам нужно найти среднее арифметическое абсцисс и ординат обоих медоид. На экран будем выводить абсолютное значение полученных чисел, умножая каждое на 10 000.

Весь код для решения файла А этого задания будет таким:

В результате получаем один из двух ответов: 10738 30730.
Осталось адаптировать своё решение для файла Б. Для начала давайте построим точечную диаграмму на основе данных этого файла.
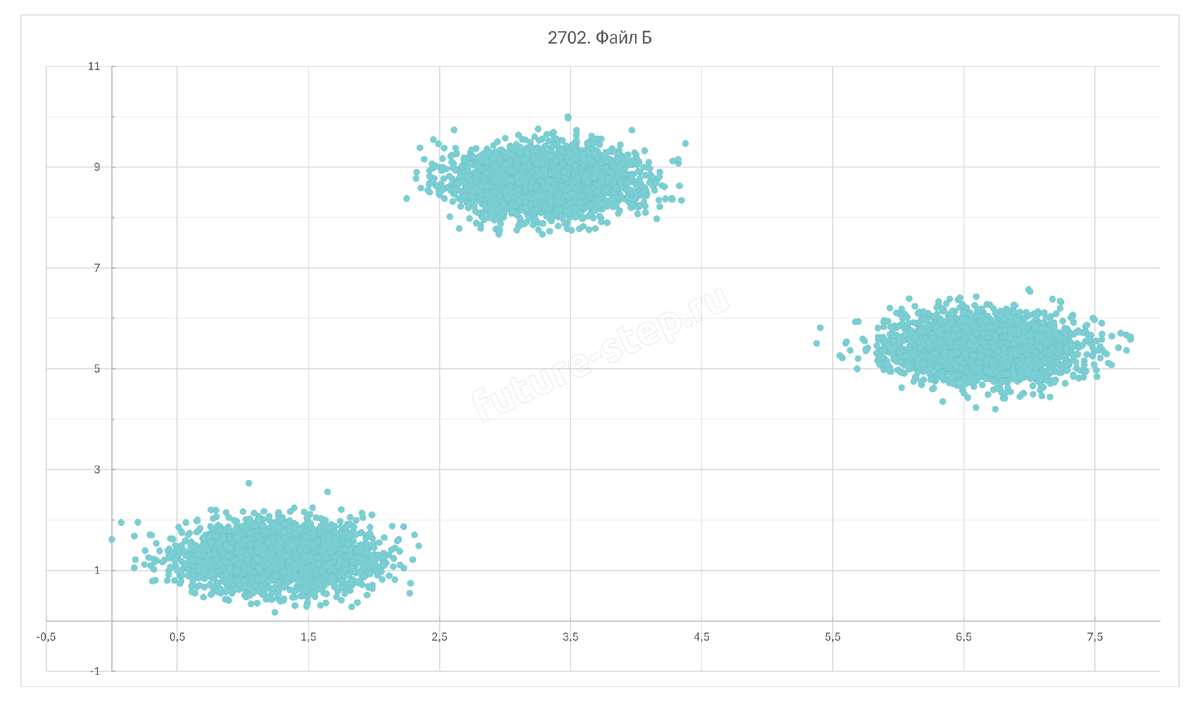
Здесь кластеры отлично разделяются прямыми, параллельными оси абсцисс. Так, точки первого кластера лежат ниже прямой y = 3, точки второго кластера – выше прямой y = 7. Третий кластер (самый правый) можем определить как тот, точки которого лежат между прямыми y = 3 и y = 7. Или просто все оставшиеся точки, не вошедшие в первые два кластера, будем относить к третьему.
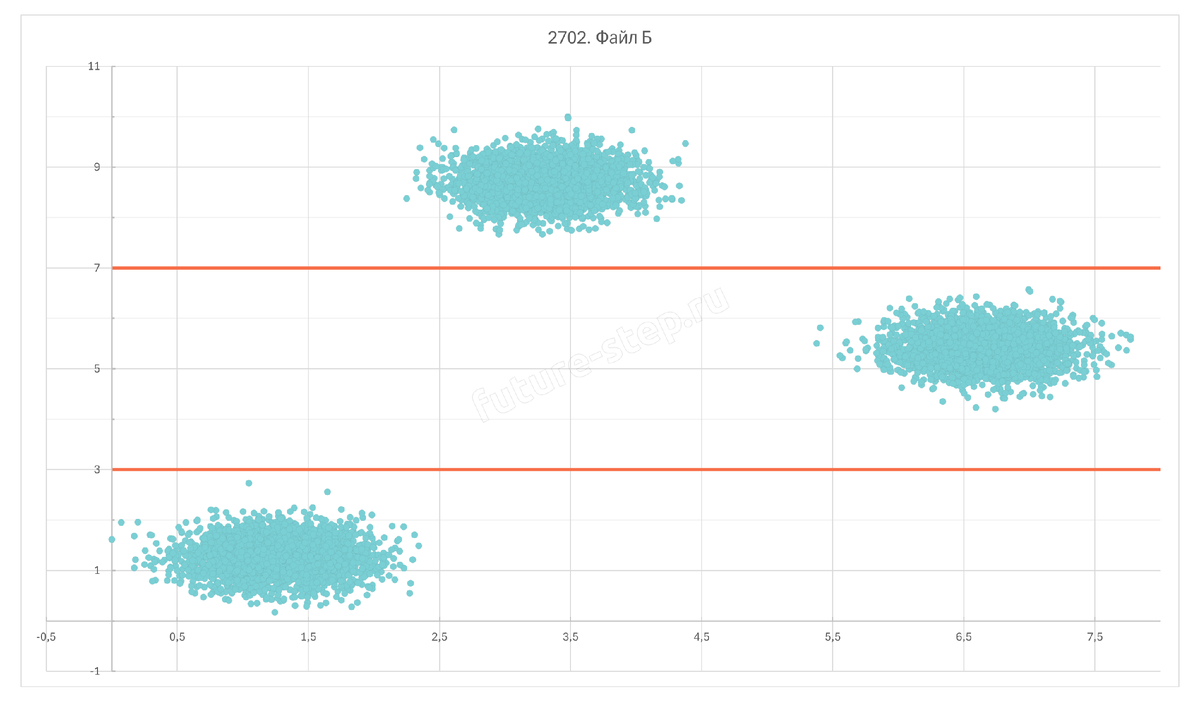
В коде это будет реализовано так:

Осталось лишь добавить строку кода для вычисления третьей медоиды и поправить вычисление среднего арифметического. Полный код для решения файла Б будет таким:

И мы получили второй ответ к данному заданию: 37522 51277.
Пример
Решим еще одно задание этим методом. Формулировка будет такой:
Задание 2701
«Фрагмент звёздного неба спроецирован на плоскость с декартовой системой координат. Учёный решил провести кластеризацию полученных точек, являющихся изображениями звёзд, то есть разбить их множество на N непересекающихся непустых подмножеств (кластеров), таких, что точки каждого подмножества лежат внутри прямоугольника со сторонами длиной H и W, причём эти прямоугольники между собой не пересекаются. Стороны прямоугольников не обязательно параллельны координатным осям.
Гарантируется, что такое разбиение существует и единственно для заданных размеров прямоугольников.
Будем называть центром кластера точку этого кластера, сумма расстояний от которой до всех остальных точек кластера минимальна. Для каждого кластера гарантируется единственность его центра. Расстояние между двумя точками на плоскости A(x1,y1) и B(x2,y2) вычисляется по формуле:
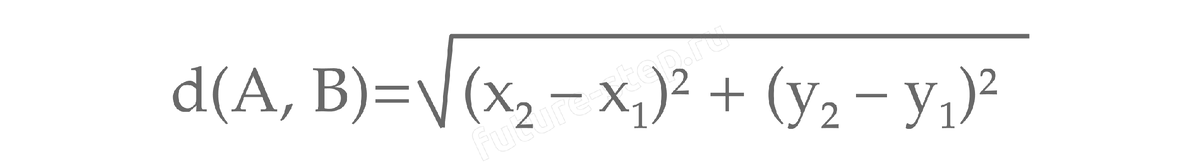
В файле A хранятся данные о звёздах двух кластеров, где H=11, W=11 для каждого кластера. В каждой строке записана информация о расположении на карте одной звезды: сначала координата x, затем координата y. Значения даны в условных единицах. Известно, что количество звёзд не превышает 100.
В файле B хранятся данные о звёздах трёх кластеров, где H=13, W=13 для каждого кластера. Известно, что количество звёзд не превышает 10 000. Структура хранения информации о звездах в файле B аналогична файлу А.
Для каждого файла определите координаты центра каждого кластера, затем вычислите два числа: Px – среднее арифметическое абсцисс центров кластеров, и Py – среднее арифметическое ординат центров кластеров.
В ответе запишите четыре числа: в первой строке сначала абсолютное значение целой части произведения Px × 10 000, затем абсолютное значение целой части произведения Py × 10 000 для файла А, во второй строке – аналогичные данные для файла B»
Начнём все так же с визуализации данных из файла А.
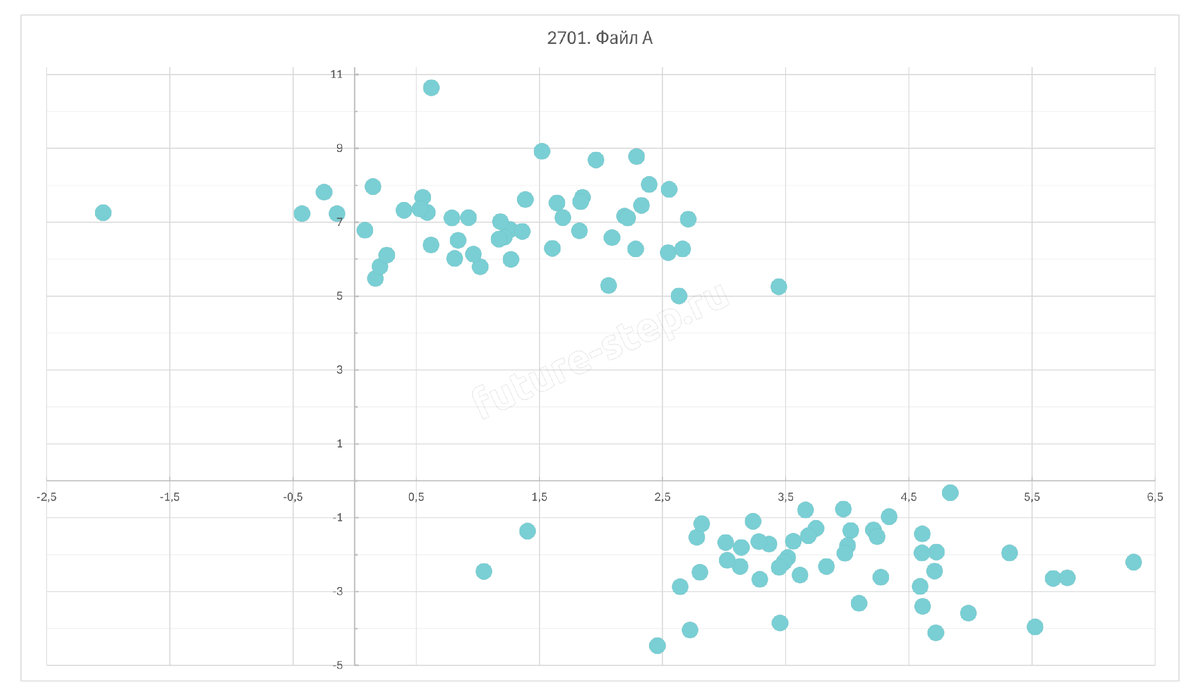
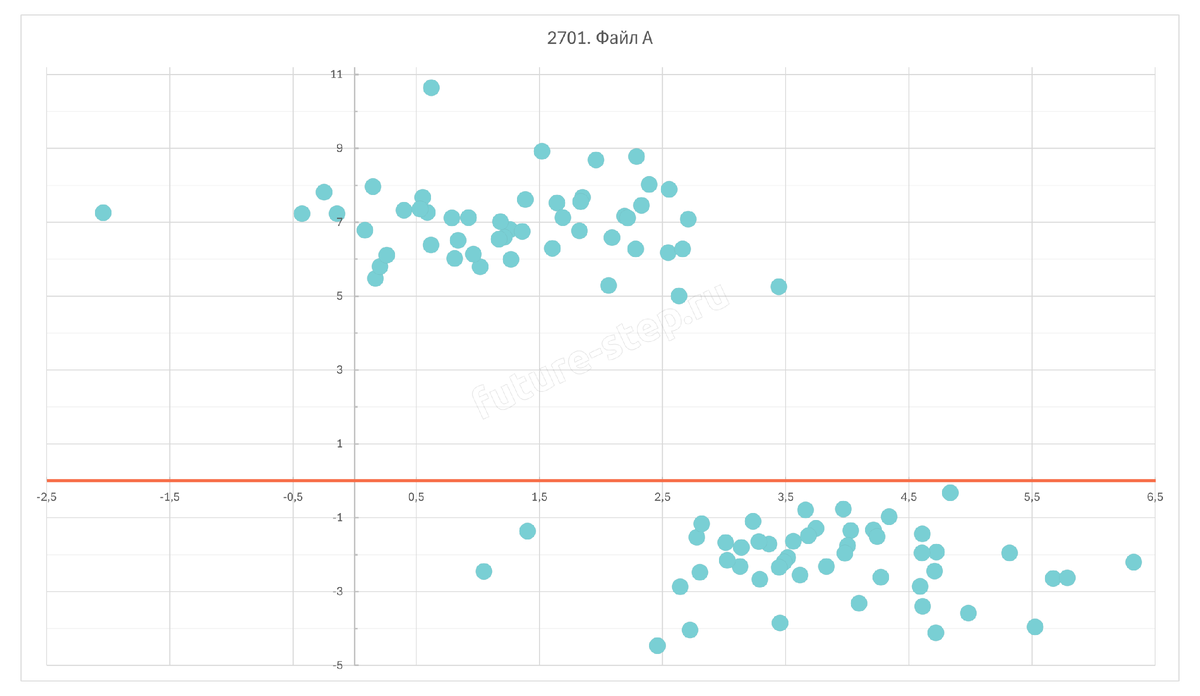
Здесь кластеры можем разделить прямой y = 0. В таком случае те точки, ордината которых меньше 0 будут отходить первому кластеру, а в противном случае – ко второму.
Код можем использовать тот же самый, что был в прошлом задании. Но давайте немного оптимизируем его. Согласитесь, довольно неудобно писать по несколько строчек для поиска медоиды каждого кластера? Лучше реализуем поиск медоид через списочное вложение, например, так:

Тогда перед чтением данных из файла создаём список из двух пустых списков, по количеству кластеров (для файла Б будет три пустых списка).

Далее считываем данные как обычно и в каждый из вложенных списков добавляем соответствующие точки:

Находим медоиды списочным выражением, написанным выше, а затем через функцию sum() складываем сначала абсциссы, затем ординаты медоид и делим на количество медоид, получая тем самым среднее арифметическое:

Такая запись более прозрачна, легче читается и убережёт вас от ошибок: не забудете добавить еще одну медоиду для файла Б и не ошибётесь в индексах.
А весь код для решения файла А будет выглядеть так:

На выходе получаем пару чисел: 26216 24182.
Переходим к файлу Б. Также визуализируем точки из него.
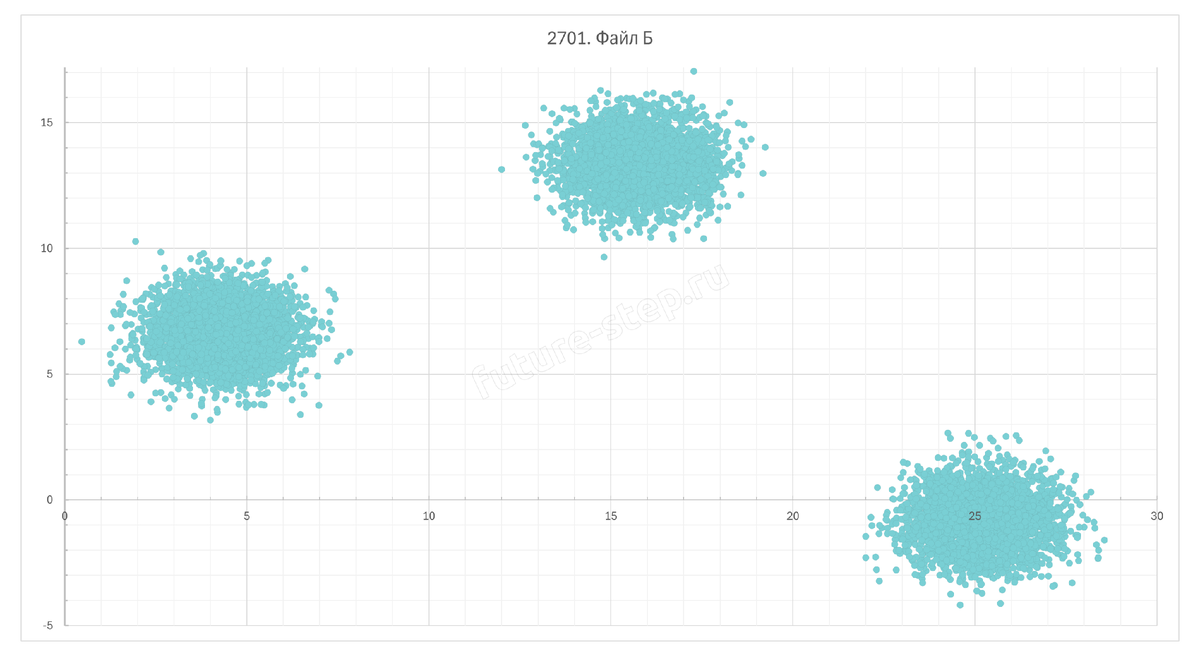
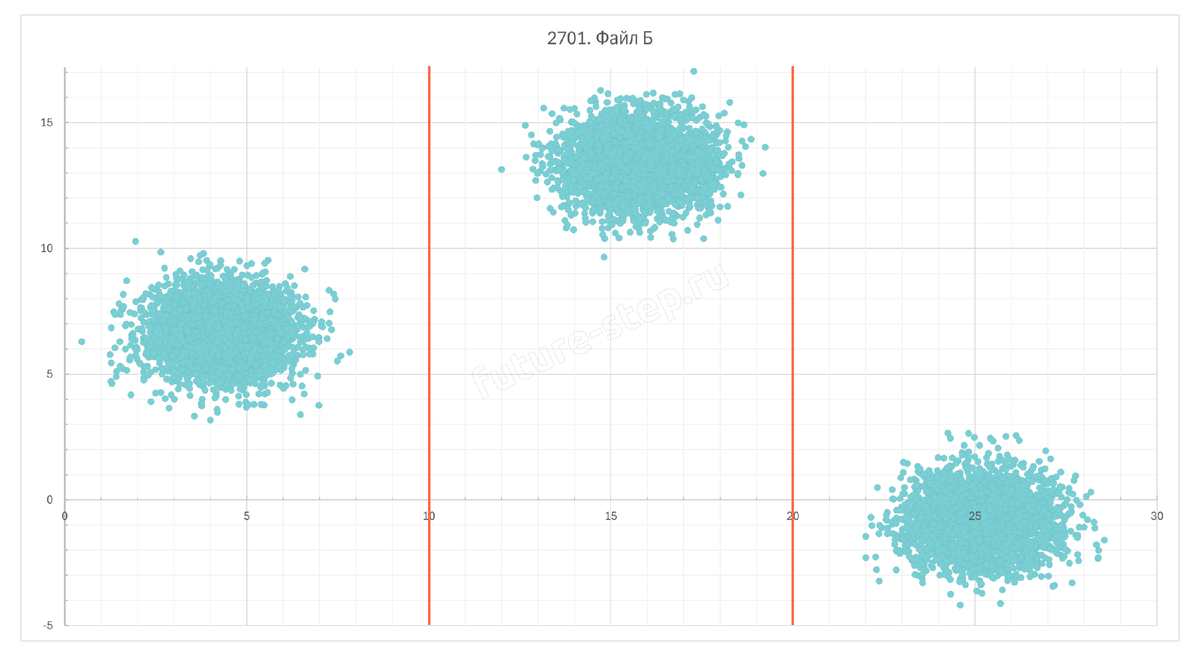
Здесь кластеры прекрасно разделяются прямыми x = 10 и x = 20.
Переходим к решению кодом. Не забываем добавить еще один пустой список в clusters:

Считываем данные и распределяем каждую точку в свой список.

На этом все отличия от прошлого кода закончились. Полный код будет выглядеть так:

После завершения работы программы получаем вторую пару чисел, которую и запишем в ответ к этому заданию: 150891 63754.
На этом мы и завершим разбор алгоритма кластеризации через уравнения прямых.