

Задача №1
При регистрации в компьютерной системе каждому пользователю выдаётся пароль, состоящий из 10 символов. В качестве символов используются прописные и строчные буквы латинского алфавита, т.е. всего 52 различных символа. В базе данных для хранения каждого пароля отведено одинаковое и минимально возможное целое число байт. При этом используется посимвольное кодирование паролей, все символы кодируются одинаковым и минимально возможным количеством бит. Определите объём памяти (в Кбайтах), необходимый для хранения данных о 65 536 пользователях. В ответе запишите только целое число – количество Кбайт.
Решение
Выбор количества бит
Для формирования пароля можно использовать 52 символа.
Чтобы закодировать 52 различные комбинации необходимо не менее 6 бит.
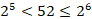
Нахождение длины для объекта (в битах и в байтах)
В каждом пароле по 10 символов. Поэтому 1 пароль будет состоять из 6‧10 = 60 бит.
По условию задачи пароль нужно сохранить с помощью минимального целого количества байт.
Значит количество байт должно быть не менее ![]() Байт. Следовательно, для хранения одного пароля выделяется 8 байт.
Байт. Следовательно, для хранения одного пароля выделяется 8 байт.
Вычисление размера файла
По условию задачи сохраняется информация о 65536 пользователях. Так как никакая другая информация, кроме паролей не сохраняется (этой информации не описано в условии), следовательно, необходимо узнать объем памяти, необходимый для хранения 65536 паролей и перевести данный размер в Кбайты.
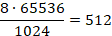
Ответ: 512 Кбайт
Запишем представленное выше решение на Python
from math import log2, ceil
# размер кодировочной таблицы
kod = 52
# количество бит на один символ
# минимальная степень 2, большая или равная kod
char = ceil( log2(kod) )
# количество Байт на 1 пароль.
# минимальное ЦЕЛОЕ количество Байт,
# достаточное для хранения 10 символов
pas = ceil( 10*char/8 )
# количество Кбайт на 65536 паролей
print(65536*pas/1024)
# 512
Задача №2
При регистрации в компьютерной системе каждому пользователю выдаётся пароль, состоящий из 7 символов и содержащий только символы из 12-буквенного набора А, В, Е, К, М, Н, О, Р, С, Т, У, X. В базе данных для хранения сведений о каждом пользователе отведено одинаковое и минимально возможное целое число байт. При этом используют посимвольное кодирование паролей, все символы кодируются одинаковым и минимально возможным количеством бит. Кроме собственно пароля для каждого пользователя в системе хранятся дополнительные сведения, для чего отведено 15 байт. Определите объём памяти в байтах, необходимый для хранения сведений о 150 пользователях.
Решение
Заметим, что теперь сохраняется два поля: пароль и дополнительные сведения. Размер доп.сведений задан и равен 15 байтам. Поэтому найдем размер поля для хранения пароля.
Выбор количества бит на символ в пароле
Для формирования пароля можно использовать 12 символов.
Чтобы закодировать 12 различных комбинаций необходимо не менее 4 бит.
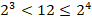
Нахождение длины для пароля (в битах и в байтах)
В каждом пароле по 7 символов. Поэтому 1 пароль будет состоять из 4‧7 = 28 бит.
По условию задачи пароль нужно сохранить с помощью минимального целого количества байт.
Значит количество байт должно быть не менее ![]() Байт. Следовательно, для хранения одного пароля выделяется 4 байта.
Байт. Следовательно, для хранения одного пароля выделяется 4 байта.
Вычисление размера файла
По условию задачи сохраняется информация о 150 пользователях. Находим общую длину пароля и доп.сведений в байтах, после чего находим объем памяти, необходимый для хранения 150 записей.
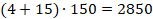
Ответ: 2850 байт
Запишем это же решение на Python
from math import log2, ceil
# размер кодировочной таблицы
kod = 12
# количество бит на один символ
# минимальная степень 2, большая или равная kod
char = ceil( log2(kod) )
# количество Байт на 1 пароль.
# минимальное ЦЕЛОЕ количесто Байт,
# достаточное для хранения 10 символов
pas = ceil( 7*char/8 )
# количество байт на 150 пользователей
# с учетом дополнительных сведений
print((pas+15)*150)
# 2850
Обратные задачи
Также в задачах по условию может быть необходимо найти и другие характеристики кодирования, если известен общий размер данных.
Задача 3
При регистрации в компьютерной системе каждому пользователю выдаётся пароль, состоящий из 15 символов и содержащий только символы из 12-символьного набора: А, В, C, D, Е, F, G, H, K, L, M, N. В базе данных для хранения сведений о каждом пользователе отведено одинаковое и минимально возможное целое число байт. При этом используют посимвольное кодирование паролей, все символы кодируют одинаковым и минимально возможным количеством бит. Кроме собственно пароля, для каждого пользователя в системе хранятся дополнительные сведения, для чего выделено целое число байт; это число одно и то же для всех пользователей. Для хранения сведений о 20 пользователях потребовалось 300 байт. Сколько байт выделено для хранения дополнительных сведений об одном пользователе?
Решение
Выбор количества бит
Для формирования пароля можно использовать 12 символов.
Чтобы закодировать 12 различных комбинаций необходимо не менее 4 бит.
Нахождение длины для пароля (в битах и в байтах)
В каждом пароле по 15 символов. Поэтому 1 пароль будет состоять из 4‧15 = 60 бит.
По условию задачи пароль нужно сохранить с помощью минимального целого количества байт.
Значит количество байт должно быть не менее ![]() Байт. Следовательно, для хранения одного пароля выделяется 8 байт.
Байт. Следовательно, для хранения одного пароля выделяется 8 байт.
Вычисление размера записи
Для хранения сведений о 20 пользователях потребовалось 300 байт.
Следовательно, на 1 пользователя приходится ![]() байт.
байт.
1 запись состоит из двух полей – пароля и дополнительных сведений, значит
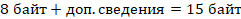
Поэтому на дополнительные сведения отводится
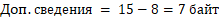
Ответ: 7 байт
Запись решения на Python
from math import *
# размер кодировки
kod = 12
# размер одного символа в битах
char = ceil( log2(kod) )
# размер пароля в Байтах
pas = ceil( 15*char/8 )
# размер записи о пользователе
user = 300/20
# размер поля с дополнительными сведениями
print(user-pas)
Однако при программном способе решения можно перебрать все варианты, которые подходят по условию задачи, и выбрать наибольший из них. При этом воспользовавшись цепочкой вычислений, которой мы пользовались при решении предыдущих задач.
from math import *
# размер кодировки
kod = 12
# размер одного символа в битах
char = ceil( log2(kod) )
# размер пароля в Байтах
pas = ceil( 15*char/8 )
# перебираем размер поля для
# доп.сведений в Байтах
for dop in range(1, 1000):
# размер записи
rec = pas + dop
# размер всех записей
all_rec = rec*20
# если количество данных соответствует числу из задания
if all_rec == 300:
# выводим подходящее значение
print(dop)
Задача 4
При регистрации в компьютерной системе каждому пользователю выдаётся пароль, состоящий из 11 символов. В качестве символов используют прописные и строчные буквы латинского алфавита (в нём 26 символов), а также десятичные цифры. В базе данных для хранения сведений о каждом пользователе отведено одинаковое и минимально возможное целое число байт. При этом используют посимвольное кодирование паролей, все символы кодируют одинаковым и минимально возможным количеством бит. Кроме собственно пароля, для каждого пользователя в системе хранятся дополнительные сведения, для чего выделено 13 байт на одного пользователя. В компьютерной системе выделено 1 Кбайт для хранения сведений о пользователях. О каком наибольшем количестве пользователей может быть сохранена информация в системе? В ответе запишите только целое число – количество пользователей.
Решение
Выбор количества бит
Для формирования пароля можно использовать 62 символа (26+26+10).
Чтобы закодировать 62 различных комбинаций необходимо не менее 6 бит.
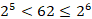
Нахождение длины для пароля (в битах и в байтах)
В каждом пароле по 11 символов. Поэтому 1 пароль будет состоять из 6‧11 = 66 бит.
По условию задачи пароль нужно сохранить с помощью минимального целого количества байт.
Значит количество байт должно быть не менее ![]() Байт. Следовательно, для хранения одного пароля нужно 9 байт.
Байт. Следовательно, для хранения одного пароля нужно 9 байт.
Вычисление размера записи
Дополнительные сведения занимают 13 байт для каждого пользователя. Поэтому запись для одного пользователя занимает 13 + 9 = 22 Байта.
Нахождение количества пользователей
Нужно найти, какое количество записей по 22 Байта можно уместить в 1 Кбайт. Для этого представим 1 Кбайт как 1024 Байта. После чего найдем количество записей
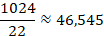
Следовательно, в 1 Кбайт можно записать не более 46 целых записей.
Ответ: 46 записей
Прямое решение на Python
from math import *
# размер кодировки и размер доп.сведений
kod, dop = 62, 13
# размер одного символа в битах
char = ceil( log2(kod) )
# размер пароля в Байтах
pas = ceil( 11*char/8 )
# размер записи
rec = pas + dop
# количество записей
print(2**10 // rec)
Переборное решение на Python
from math import *
# размер кодировки и размер доп.сведений
kod, dop = 62, 13
# размер одного символа в битах
char = ceil( log2(kod) )
# размер пароля в Байтах
pas = ceil( 11*char/8 )
# размер записи
rec = pas + dop
# перебираем количество записей о пользователях
for cnt in range(1, 10000):
# если можно записать такое количество записей,
# но нельзя записать больше
if rec*cnt <= 2**10 < rec*(cnt+1):
# выведем количество
print(cnt)
Поиск максимального/минимального значения одной из характеристик файла
Также на ЕГЭ и в базах заданий встречаются обратных задачи, где нужно найти максимальное или минимальное значение одной из характеристик.
При решении таких задач нужно учитывать ограничение на итоговый объем.
Если в условии сказано, что выделенный объем памяти Sхранения не может быть превышен, то имеем дело с выражением вида
Sвсех записей ≤ Sхранения
Если в условии сказано, что выделенного объема памяти Sхранения не хватает для хранения записей, то имеем дело с выражением вида
Sвсех записей > Sхранения
Задача №5
На предприятии каждой изготовленной детали присваивают серийный номер, содержащий десятичные цифры, 52 латинские буквы (с учётом регистра) и символы из 458-символьного специального алфавита. В базе данных для хранения каждого серийного номера отведено одинаковое и минимально возможное целое число байт. При этом используется посимвольное кодирование серийных номеров, все символы кодируются одинаковым и минимально возможным числом бит. Известно, что для хранения 862 серийных номеров отведено не более 276 Кбайт памяти. Определите максимально возможную длину серийного номера. В ответе запишите только целое число.
Количество бит на символ
Сначала определим размер кодировки: используются десятичные цифры (10), 52 латинские буквы (с учётом регистра) и символы из 458-символьного специального алфавита.
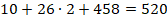
Теперь определим минимальное количество бит для равномерного кодирования 520 символов.
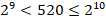
Значит на один символ приходится 10 бит.
Размер серийного номера в Байтах
Для оценки длины серийного номера составим неравенство, исходя из условия задания.
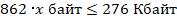
Переведем обе части в Байты.
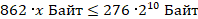
Выразим x
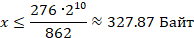
Следовательно, размер одного серийного номера не может быть больше 327 Байт.
Длина серийного номера
Теперь оценим длину одного серийного номера. Обозначим её через l и решим неравенство, зная, что каждый символ занимает 10 бит памяти, и что для хранения всего серийного номера выделено не больше 327 Байт или 327 * 8 бит:
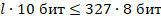
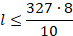
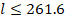
Значит длина одного серийного номера не может быть больше 261 символов.
Ответ: 261
Вычисление ответа с помощью Python
from math import *
# Размер кодировки
kod = 10 + 26*2 + 458
# Количество бит необходимое
# для хранения одного символа
char = ceil( log2(kod) )
# размер номера в Байтах
x = 276*2**10 // 862
# определение длины серийного номера
print(x*8 // 10)
Переборное решение в Python
from math import *
# Размер кодировки
kod = 10 + 26*2 + 458
# Количество бит необходимое
# для хранения одного символа
char = ceil( log2(kod) )
# переберем возможные длины номеров
for l in range(1,500):
# размер серийного номера в Байтах
nom = ceil(l*char/8)
# проверка можно ли сохранить номер такой длины
if 862*nom <= 276*1024:
print(l)
Запускаем программу, получаем результат:
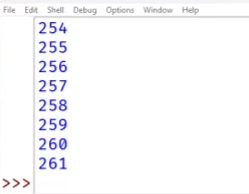
Мы перебирали последовательно длины серийного номера, начинающиеся с 2 и получали, что до 261 символа на номер, для хранения 862 серийных номеров нужно не более 276Кб памяти. Длины более 261 символа на номер не подходят, в этих случаях объем памяти превысит заданный.
Максимально возможна длина серийного номера равна 261.
Однако можно найти требуемое значение с помощью дополнительной проверки.
from math import *
kod = 10 + 26*2 + 458
char = ceil( log2(kod) )
for l in range(1,500):
nom = ceil(l*char/8)
# размер серийного номера в Байтах
# если номер будет содержать больше символов
nom_g = ceil((l+1)*char/8)
# проверка можно ли сохранить номер такой длины
# и нельзя сохранить серийный номер большей длины
if 862*nom <= 276*1024 < 862*nom_g:
print(l)
Ответ: 261
Задача №6
На предприятии каждой изготовленной детали присваивают серийный номер, содержащий десятичные цифры, 26 латинских букв (без учёта регистра) и символы из 8164-символьного специального алфавита. В базе данных для хранения каждого серийного номера отведено одинаковое и минимально возможное целое число байт. При этом используется посимвольное кодирование серийных номеров, все символы кодируются одинаковым и минимально возможным числом бит. Известно, что для хранения 835 серийных номеров отведено более 156 Кбайт памяти. Определите минимально возможную длину серийного номера. В ответе запишите только целое число.
Количество бит на символ
Сначала определим размер кодировки: используются десятичные цифры (10), 52 латинские буквы (с учётом регистра) и символы из 458-символьного специального алфавита.
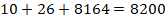
Теперь определим минимальное количество бит для равномерного кодирования 520 символов.
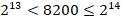
Значит на один символ приходится 14 бит.
Размер серийного номера в Байтах
Для оценки размера серийного номера составим неравенство, исходя из условия задания.
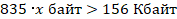
Переведем обе части в Байты.
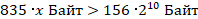
Выразим x
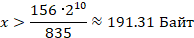
Следовательно, размер одного серийного номера должен быть больше 191 Байта.
Важно понимать, что для дальнейших вычислений нужно именно нестрогое неравенство, так как количество Байт «округляется» вверх.
Длина серийного номера
Теперь оценим длину одного серийного номера. Обозначим её через l и решим неравенство, зная, что каждый символ занимает 14 бит памяти, и что для хранения всего серийного номера выделено не больше 191 Байт или 191 * 8 бит:
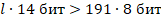
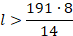
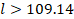
Значит длина одного серийного номера должна быть не менее 110 символов.
Ответ: 110
Вычисления с помощью Python (программа)
from math import *
# определим размер кодировки
kod = 10 + 26 + 8164
# количество бит на символ
char = ceil( log2(kod) )
# Определение размера одного серийного номера
x = 156*2**10 / 835
# Длина серийного номера
l = x*8 / char
# Если длина серийного номера получилась целым числом
if l.is_integer():
# Для превышения объема добавим еще один символ
l += 1
print(ceil(l))
Переборное решение на Python
from math import *
# определим размер кодировки
kod = 10 + 26 + 8164
# количество бит на символ
char = ceil( log2(kod) )
# перебор возможных длин
for l in range(1,500):
# размер одного номера в Байтах
nom = ceil( l*char/8 )
# если все номера занимают большй объем
if 835*nom > 156*1024:
# выведем только первое значение
print(l)
break
Задача №7
Каждое изделие, изготовленное на предприятии, получает уникальный код, состоящий из 30 символов. Каждый символ кода может быть латинской буквой (заглавной или строчной), десятичной цифрой или специальным символом из особого технического набора. В базе данных хранится список всех уже использованных кодов. При этом используется посимвольное кодирование, каждый символ кодируется одинаковым минимально возможным числом бит, а для хранения каждого кода отводится одинаковое минимально возможное число байт. Известно, что для хранения списка из 5200 кодов выделено не более 150 Кбайт. Какое наибольшее количество специальных символов может входить в особый технический набор?
Длина кода в байтах
Найдем максимальный размер в байтах уникального кода. Для этого предоставленный объем разделим на количество кодов.
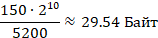
Значит, один код не может занимать больше 29 целых байт. Или 29‧8 = 232 бита.
Количество бит на символ
Для нахождения верхней оценки количества бит на символ разделим максимально допустимую длину кода в битах на количество символов в коде.
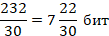
Так как найдена верхняя оценка, нельзя взять большее значение. Поэтому максимальное количество бит на символ может быть равно 7.
Количество специальных символов
Так как на 1 символ приходится по 7 бит, то количество возможных вариантов для каждого символа соответствует неравенству
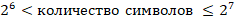
Или в целых числах
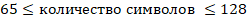
Подставим данные из задачи
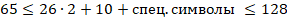
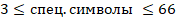
Следовательно, наибольшее количество специальных символов равно 66.
Ответ: 66
Решение на Python (перебор)
from math import *
# перебор возможных количеств спец.символов
for dop in range(1,1000):
# размер кодировки
kod = 26+26+10+dop
# минимальное количество бит на 1 символ кодировки
char = ceil( log2(kod) )
# минимальное количество Байт на код
kod = ceil(30*char/8)
# если можно сохранить
if 5200*kod <= 150*1024:
# выводим количество спец.символов
print(dop)
Запускаем программу, получаем результат, список значений:

Наибольшее число в этом списке, то есть наибольшее количество специальных символов, которое может входить в особый технический набор, равно 66.
Задача №8
На предприятии каждой изготовленной детали присваивают серийный номер, состоящий из 261 символов. Для его хранения отведено одинаковое и минимально возможное целое число байт. При этом используется посимвольное кодирование серийных номеров, все символы кодируются одинаковым и минимально возможным числом бит. Известно, что для хранения 252 500 серийных номеров отведено более 31 Мбайт памяти. Определите минимально возможную мощность алфавита, из которого составляются серийные номера. В ответе запишите только число.
Решение
Мощность алфавита – это размер кодировки, то есть в данной задаче нужно определить, какой минимальный размер кодировки должен быть, чтобы выполнилось условие, что для хранения 252 500 серийных номеров отведено более 31 Мбайт памяти.
Оценим размер серийного номера в байтах, обозначим его за x и решим неравенство, зная, что для хранения 252 500 серийных номеров отведено более 31 Мбайт памяти, то есть более чем 31‧1024‧1024 Байт:
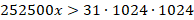
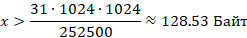
Значит серийный номер должен занимать больше 128 Байт или 1024 бит.
Минимальное количество бит на символ
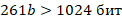
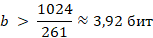
Следовательно, bmin= 4 бита.
Определение мощности
Найдем значение по формуле
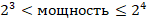
Или
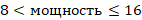
То есть в алфавите может быть от 9 до 16 символов.
Минимальная мощность – 9.
Ответ: 9
Решение в Python
from math import *
# перебираем возможные мощности алфавитов
for kod in range(1,1000):
# определяем количество бит на символ
char = ceil( log2(kod) )
# определяем количество Байт на номер
nom = ceil( 261*char/8 )
# если при перебираемой мощности общий
# суммарный размер превосходит заданный объем
if 252_500*nom >31*1024*1024:
# выводим на экран только минимальное значение
print(kod)
break