

Некоторые рекомендации о том, как описать проект.
Задача №1
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, Ж, З, И, Й. решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В, Г, Д, Е, Ж, З, И использовали соответственно кодовые слова 1010, 1101, 010, 00, 1000, 1110, 1001, 0111, 1011. Укажите кратчайшее возможное кодовое слово для буквы Й, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Решение
Нарисуем дерево кодов, используя известные кодовые слова:
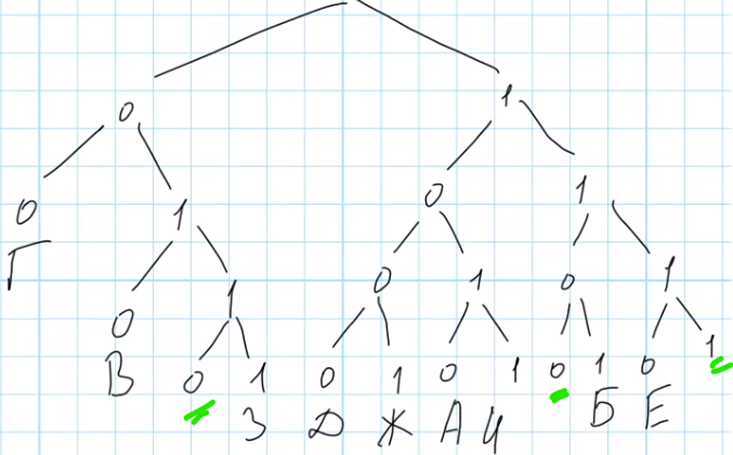
Видно, что есть три свободные «ветви» дерева кодов, где можно разместить букву Й – это ветви 0-1-1-0, 1-1-0-0 и 1-1-1-1. Все они имеют одинаковую длину, поэтому в ответе будем указывать код, имеющий наименьшее числовое значение, то есть код 0110. Это число – ответ на задачу.
Ответ: 0110
Задача №2
(Досрочный ЕГЭ-2023) По каналу связи передаются сообщения, содержащие только буквы А, Б, В, Г, Д, Е, Ж, З, И, К. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для букв известны: А – 0010, Б – 0011, В – 000, Е – 0101, Ж – 111, З – 0110, И – 101, К – 100. Найдите код минимальной длины для буквы Г. Если таких кодов несколько, укажите код с минимальным числовым значением.
Решение
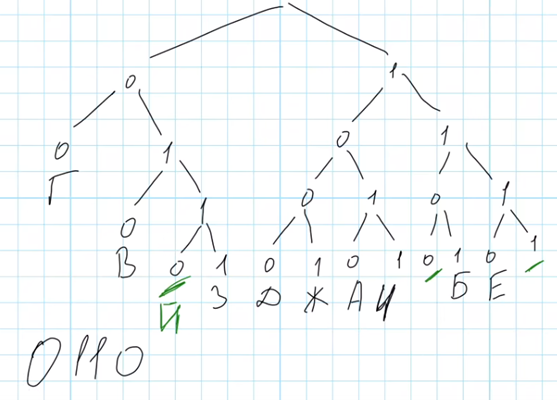
Нарисуем дерево кодов, используя известные кодовые слова:
Незакодированными остались две буквы, Г и Д, и на дереве есть две свободные ветви – 1-1-0 и 0-1-0-0. 110 – это код длиной 3, а 0100 – код длиной 4. Для буквы Г выбираем кратчайший код, 110, это число – ответ на задачу.
Обратим внимание, что всегда выбирается тот код, в котором меньшее количество цифр, и только в том случае, если есть несколько кодов одинаковой длины, нужно смотреть на числовое значение кода.
Ответ: 110
Задача №3
(ЕГЭ-2023) По каналу связи передаются сообщения, содержащие только восемь букв: А, Б, В, Г, Д, Е, Ж и 3. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: А – 000, Б – 001, В – 0101, Г – 0100, Д – 011. Какое наименьшее количество двоичных знаков потребуется для кодирования трёх оставшихся букв? В ответе запишите суммарную длину кодовых слов для букв: Е, Ж, 3.
Решение
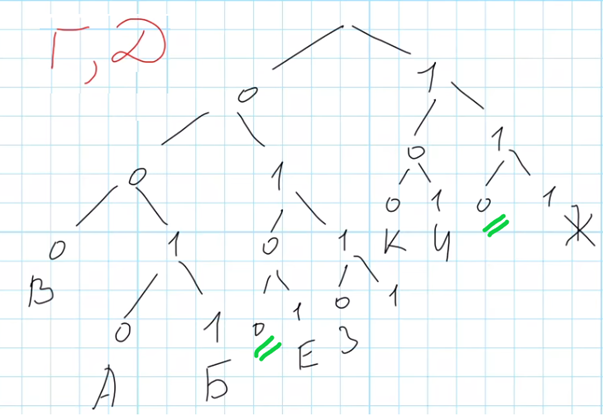
Нарисуем дерево известных кодов в соответствии с условием задачи:
Есть только одна свободная ветвь – 1, а нужно закодировать три буквы. Раздвоим эту ветвь, и одну из получившихся ветвей тоже. В данном случае неважно, какую из ветвей раздваивать и каким образом размещать буквы, потому что нас интересует суммарная длина кодовых слов для трех букв. Расставим буквы так:
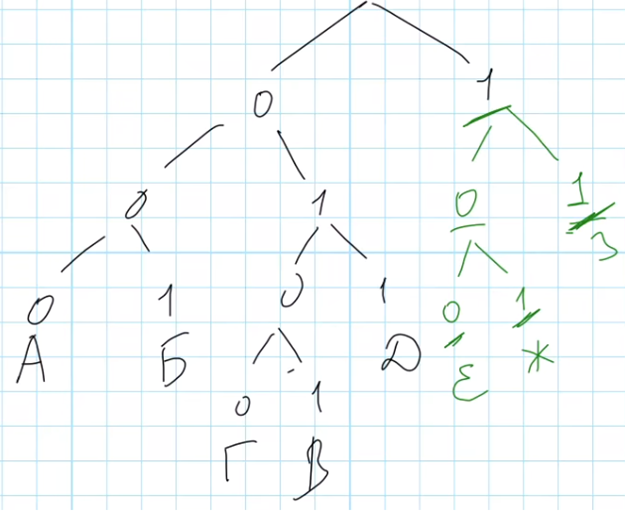
Буква Е получила код 100, длиной 3, буква Ж – код 101, длиной 3, и буква З – код 11, длиной 2.
Суммарная длина кодовых слов для букв Е, Ж, З равна 3 + 3 +2 = 8. Это число – ответ на задачу.
Ответ: 8
Задача №4
(ЕГЭ-2024) По каналу связи передаются сообщения, содержащие только десять букв: А, Б, Е, И, К, Л, Р, С, Т, У. Для передачи используется неравномерный двоичный код, удовлетворяющий условию Фано. Для девяти букв кодовые слова известны:
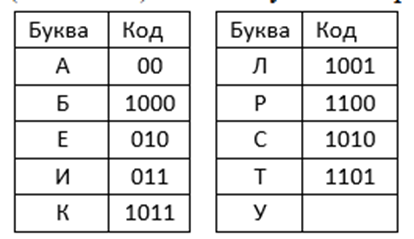
Укажите кратчайшее кодовое слово для буквы У, при котором код будет удовлетворять условию Фано. Если таких кодов несколько, укажите код с наибольшим числовым значением.
Решение
Нарисуем дерево известных кодов в соответствии с условием задачи:
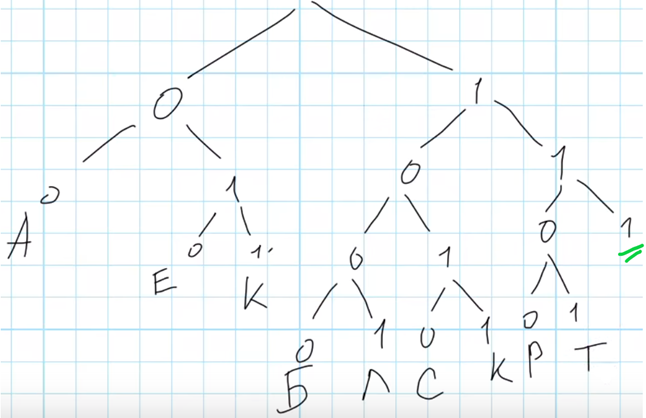
Есть только одна свободная ветвь 1-1-1 и только одна буква для кодирования – У. Следовательно, единственной букве будет соответствовать единственный свободный код – 111. Это число – ответ на задачу.
Ответ: 111
Задача №5
(ЕГЭ-2024) По каналу связи передаются сообщения, содержащие только буквы: Б, К, Л, О, Н. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: Б – 1001, К – 11. Для трёх оставшихся букв Л, Н и О кодовые слова неизвестны. Какое наименьшее количество двоичных знаков требуется для кодирования слова КОЛОКОЛ?
Решение
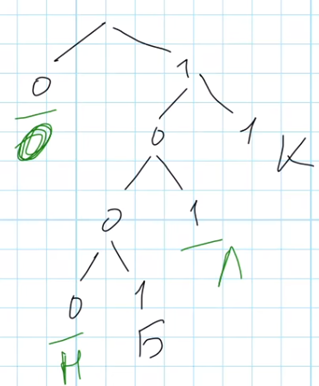
Необходимо подобрать такие коды для букв Л, Н и О, чтобы кодовое слово весило как можно меньше. Для начала составим схему, используя известные кодовые слова Б – 1001, К – 11 и посчитаем количество букв в слове КОЛОКОЛ, которое требуется закодировать:
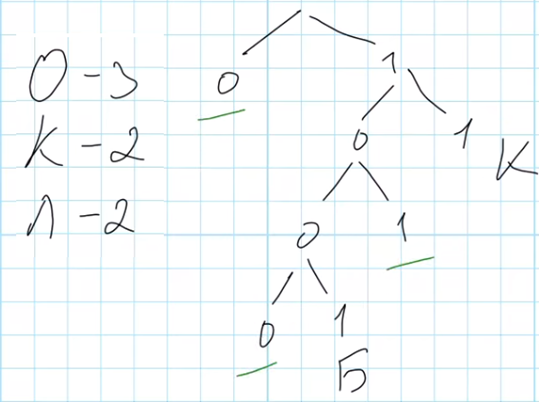
Буква О встречается в слове КОЛОКОЛ трижды, буквы Л и К – по два раза. На схеме есть три свободных места, длиной 1 (код 0), длиной 4 (код 1-0-0-0) и длиной 3 (код 1-0-1).
Нам нужно закодировать 3 буквы – О, Л и Н. Очевидно, что, раз буква О встречается в слове трижды, её нужно закодировать кодом минимальной длины, то есть кодом 0. Буква Н не встречается вовсе, поэтому она может быть закодирована длинным кодом, то есть кодом 1000. И буква Л встречается два раза, её код будет 101.
Наименьшее количество двоичных знаков требуется для кодирования слова КОЛОКОЛ посчитаем как суммарную длину всех кодов для букв, встречающихся в слове:
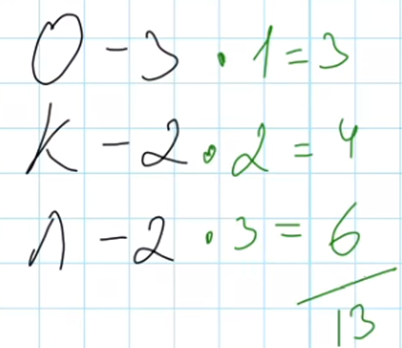
Получили результат, количество двоичных знаков равно 13. Это ответ на задачу.
Ответ: 13
Задача №6
(ЕГЭ-2022) По каналу связи передаются сообщения, содержащие только буквы из набора: А, З, К, Н, Ч. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: Н – 1111, З – 110. Для трёх оставшихся букв А, К и Ч кодовые слова неизвестны. Какое количество двоичных знаков потребуется для кодирования слова КАЗАЧКА, если известно, что оно закодировано минимально возможным количеством двоичных знаков?
Решение
Необходимо подобрать такие коды для букв А, К и Ч, чтобы кодовое слово весило как можно меньше. Для начала составим дерево, используя известные кодовые слова Н – 1111, З – 110 и посчитаем количество букв в слове КАЗАЧКА, которое требуется закодировать:
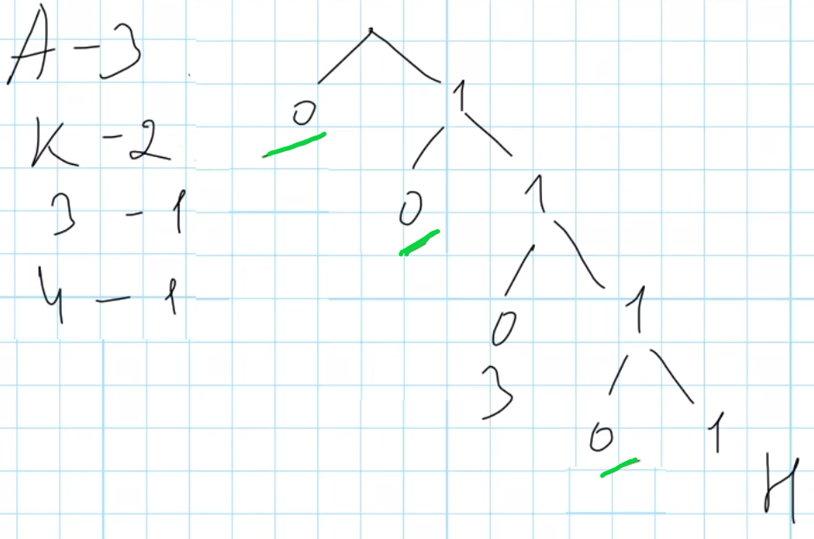
Буква А встречается в слове КАЗАЧКА трижды, буква К – два раза, буквы З и Ч по одному. На схеме есть три свободных места, длиной 1 (код 0), длиной 2 (код 10) и длиной 3 (код 1-1-1-0).
Нам нужно закодировать 3 буквы – А, К и Ч. Очевидно, что, раз буква А встречается в слове трижды, её нужно закодировать кодом минимальной длины, то есть кодом 0. Буква К встречается два раза, её код будет следующим по длине, то есть 10. Буква З уже закодирована, и для буквы Ч остается код 1110.
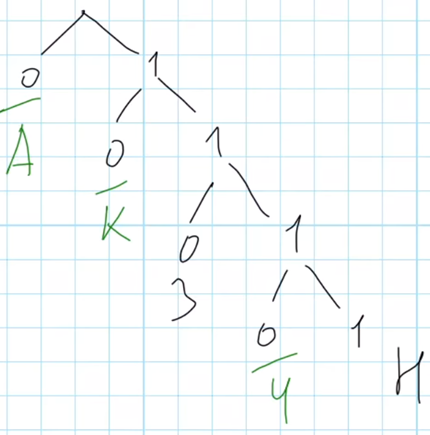
Наименьшее количество двоичных знаков требуется для кодирования слова КАЗАЧКА посчитаем как суммарную длину всех кодов для букв, встречающихся в слове:

Получили результат, количество двоичных знаков равно 14. Это ответ на задачу.
Ответ: 14
Задача №7
Все заглавные буквы русского алфавита закодированы неравномерным двоичным кодом, в котором никакое кодовое слово не является началом другого кодового слова. Это условие обеспечивает возможность однозначной расшифровки закодированных сообщений. Кодовые слова для некоторых букв известны: А – 000, Б – 01, В – 100, Г – 11, Д – 001. Укажите возможный код минимальной длины для буквы Я. Если таких кодов несколько, укажите тот из них, который имеет минимальное числовое значение.
Решение
Если ранее задания содержали строгие рамки, скажем, было указано конкретное количество символов («семь букв» или «восемь»), то теперь речь идёт обо всех прописных буквах русской азбуки, которых ровно тридцать три. Разумеется, кодировать каждую букву вручную вовсе необязательно, однако учитывать этот факт крайне важно.
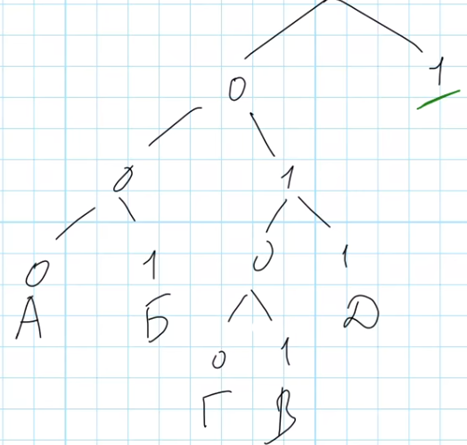
Построим дерево кодирования, используя информацию из условия задачи:
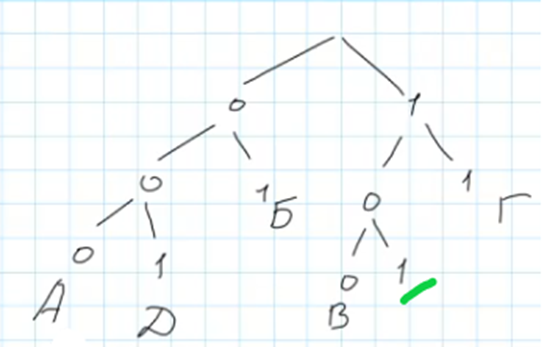
Теперь нам предстоит выбрать оптимальный путь для буквы «Я». Сразу отметим свободную ветку 1-0-1 рядом с буквой «В». Можно было бы разместить букву Я там, но такой подход неверен, поскольку дальнейшее расширение дерева становится невозможным, и разместить оставшиеся буквы будет негде.
Следовательно, нужно создать новые ветви от корня 101: 1-0-1-0 и 1-0-1-1. На одну из ветвей запишем букву Я, а вторую можно разделять для кодирования оставшихся букв, нас не интересует как именно они будут закодированы.
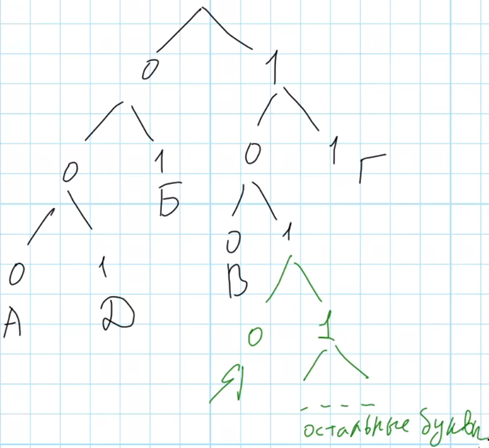
В задаче требуется указать код минимально возможной длины и имеющий минимальное числовое значение, соответственно это будет код 1010.
Ответ: 1010